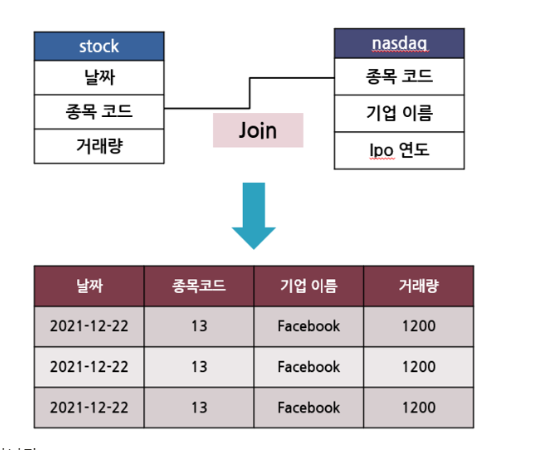
AARRR의 의미AARRR은 사용자 흭득(Acquisition) > 사용자 활성화(Activation)> 사용자 유지(Retention) > Revenue (매출)> Referral(전파) 등 유저의 서비스 이용 사이클을 체계화한 프레임 워크임.Retention 지표중요한 이유: Acquisition, Activation에 집중해서 사용자들이 새로 들어왔다 해도, 매력을 느끼지 못하면 이탈을 할 가능성이 있음. 그렇기 때문에 새로운 사용자들을 받는 것 보다 집중해야 하는것이, 기존 사용자들이 서비스를 만족스럽게 사용하고 있는지 지속적으로 사용하는 것인지 보는 Retention 지표임. 여기서 지속적 사용은 어떤 기준인가?제품의 '핵심 가치'를 기준으로 지속적으로 이용하는지 가치를 측정함.리텐션의 종류클래..